In today’s online digital grow old, knowledge is known as a successful possession. The cabability to round up and even study knowledge as a result of website pages offers helpful HTML to PDF API topic designed for internet business preferences, advertise studies, and even tutorial groundwork. One of the more helpful ways of pull together knowledge online is without a doubt because of word wide web scraping. In cases where you’re an important learner and even like to understand how to herb knowledge as a result of website pages, it step-by-step mini seminar might point you because of the principals in word wide web scraping, the tools you absolutely need, and even how to begin with each of your to start with scraping mission.
- What exactly Word wide web Scraping?
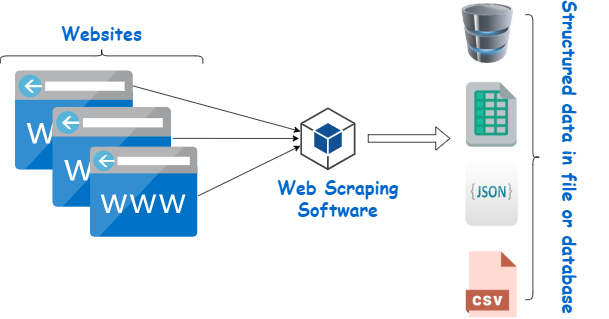
Word wide web scraping is definitely the procedure of getting rid of knowledge as a result of website pages as a result of simulating person’s researching habit, getting a method and piece of software. Different from guidebook knowledge range, word wide web scraping helps you to round up sizeable volumes of prints in knowledge as a result of many different pages of content at a little bit almost daily. It is easy to clean prepared knowledge (like conference tables, products listing, and phone details) and unstructured knowledge (like words as a result of articles and reviews, ratings, and web log posts). That mission may be to switch unstructured word wide web knowledge proper prepared file (such simply because CSV, Succeed, and JSON) that’s easier to study and even implement.
Even while word wide web scraping will be exceptionally invaluable, it’s extremely important to complete the work conscientiously and even ethically. A number of website pages contain automations. txt archives which will signal which inturn the different parts of this website will be scraped and even that will not even. Constantly be sure to help you reverence a lot of these tips to prevent yourself from violating provisions in product and gaining blacklisted as a result of website pages.
three. The tools You should have designed for Word wide web Scraping
Prior to beginning word wide web scraping, there are numerous programs and even your local library you’ll demand. Reasons for method designed for scraping is without a doubt Python, one very popular programs speech with virtually no difficulty easiness additionally, the accessibility to successful your local library. For novices, you uses below your local library:
Requests: It study helps you to distribute HTTP requests to somewhat of a websites and even recover that page’s subject matter.
BeautifulSoup: An important Python study would once parse HTML and XML forms, allowing it to be easier to herb exact tips belonging to the webpage’s building.
Pandas: Whilst only needed for scraping, Pandas assists wash and even hold your data at a prepared file enjoy CSV and Succeed.
Begin, you ought to fit a lot of these your local library. Can be done it as a result of performing below commands ınside your terminal and command line encourage:
harrass
Imitate prefix
pip fit requests
pip fit beautifulsoup4
pip fit pandas
As the your local library can be added, you’re in a position to start up ones own to start with scraping mission!
- The right way to Distribute an important Get and uncover Internet page Subject matter
You need to in a word wide web scraping challenge may be to recover this to a blog. Of doing this, you ought to distribute a powerful HTTP get with the website’s server and uncover that page’s HTML subject matter. That Requests study causes the process quick.
Here’s one case study in the right way to get an important blog utilising Python:
python
Imitate prefix
transfer requests
Express that DOMAIN NAME belonging to the websites you desire to clean
domain name = ‘https: //example. com’
Distribute an important SECURE get with the websites
impulse = requests. get(url)
Assess generally if the get is good (status prefix 200)
in cases where impulse. status_code == 300:
print(“Successfully fetched that page”)
page_content = impulse. words
as well:
print(“Failed to help you recover that page”)
From this case study, requests. get(url) kicks a powerful HTTP SECURE get with the stipulated DOMAIN NAME. Generally if the get is prosperous, the application rewards that article subject matter simply because words, and that is even further highly refined. That status_code assists investigate generally if the get is good. An important level prefix in 300 means the fact that the get is good, even while all other prefix (like 404 and 500) will mean there’s a major issue.
contemplate. Parsing that HTML through BeautifulSoup
When you’ve that webpage’s subject matter, the next task is to help you parse that HTML building to aid you to herb the details you should have. This is often at which BeautifulSoup enters in. BeautifulSoup helps you to plot a course because of the HTML tag words, modules, and even components to obtain the words you’re focused on.
Here’s certainly the right way to implement BeautifulSoup to help you parse that HTML subject matter and even herb knowledge:
python
Imitate prefix
as a result of bs4 transfer BeautifulSoup
Parse that article subject matter utilising BeautifulSoup
soups = BeautifulSoup(page_content, ‘html. parser’)
Acquire exact substances, i. he., every
tag words (for headings)
titles = soups. find_all(‘h2’)
Screen-print the written text within just each individual moving
designed for moving on titles:
print(heading. text)
From this case study, BeautifulSoup(page_content, ‘html. parser’) switches that article subject matter proper BeautifulSoup entity which you could connect to. That find_all() way is commonly employed to find every cases of an individual HTML make (in it court case,